The Drupal.org Complexity
18 May 2016At DrupalCon New Orleans, during both Dries’s keynote and at the State of Drupal Core Conversation, question of whether/when to move to Github came up again.
Interestingly, I was already deep into researching ways we could reduce the cost of our collaboration tools while bringing in new contributors. This post is meant to serve as a little history of how we got to where we are and to provide information about how we might choose to go forward.
It’s complex
To say Drupal.org is complex is an understatement. There are few systems with more integration points than Drupal.org and its related sites and services.
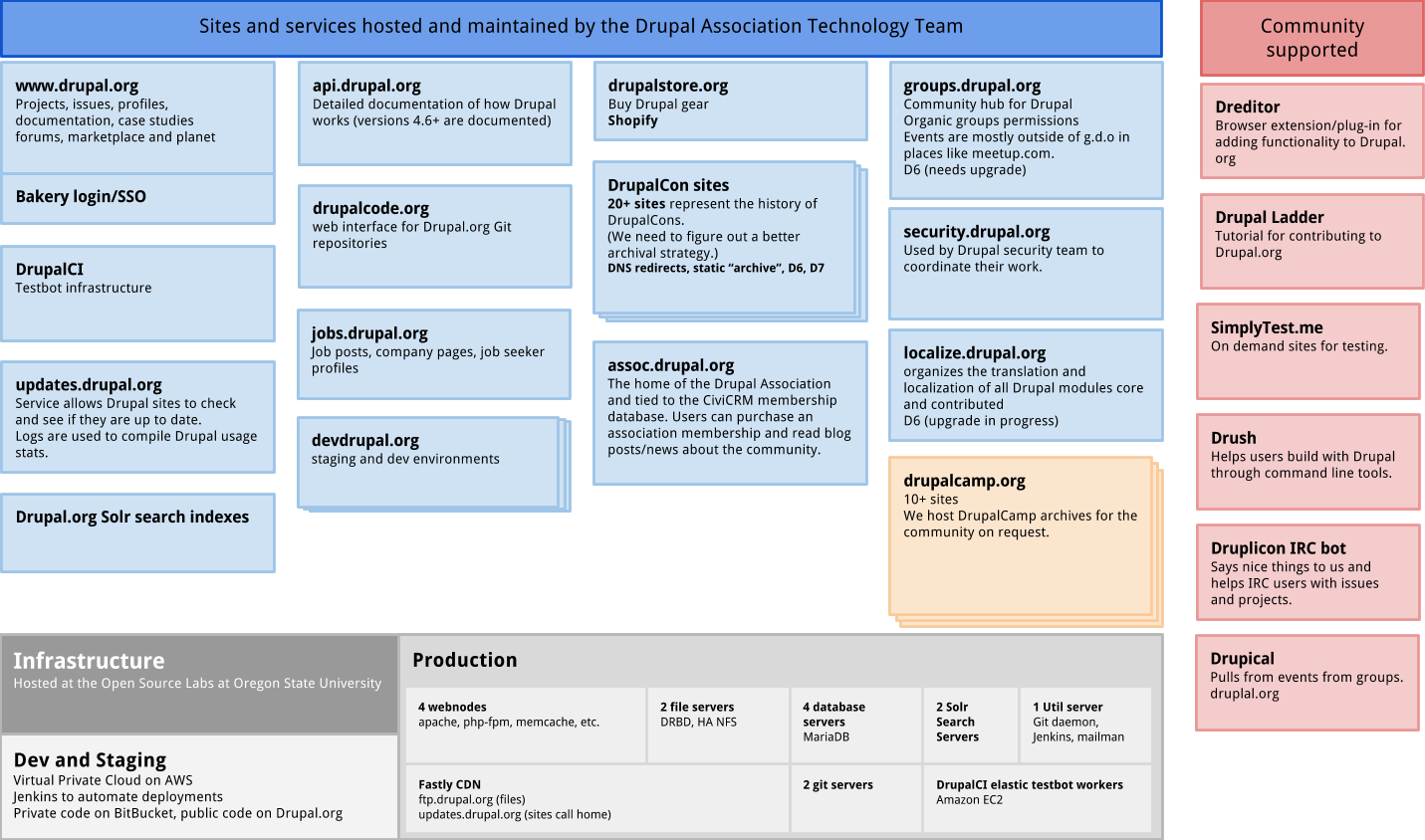
The ecosystem is complex with lots of services that share integrations like login (Bakery single sign on) and cross-site code/themes.
It all starts with the code
The slogan “come for the code stay for the community” is accurate. The community would not exist without the unifying effort of collaborating to create the code. The growth of the community is primarily because of the utility the code provides and the (relative) ease of creating a wide range of websites and applications using Drupal core combined with contributed modules and themes that allow that framework to be extended.
Drupal.org was an extension of the development of Drupal for a very long time. Up until Drupal 6, Drupal.org was always upgraded the day of the release of a new version. When Drupal was smaller with a more limited scope, this made a lot of sense. With the release of Drupal 6 and the surge in usage of Drupal, more and more contributors started working on the Drupal.org infrastructure and creating new sites and services to speed the collaborative work of the community.
One of the biggest transitions during the Drupal 6 lifecycle and community surge was The Great Git Migration. Much of the complexity of Drupal.org and the related sites and services was created during this time period. Understanding that timeline will help in understanding just how much work went into Drupal.org and Drupal at that time.
The Great Git Migration
In the Great Git Migration, all of the history of Drupal code was migrated to Git from CVS. The timeline for migrating to git was about what you would expect. Community conversation took time, getting volunteers to start the process took time, finally, there was a phase were dedicated (paid) resources were contracted to finish the work.
- May 2009 - Google Summer of Code project proposed to create tools to make the migration of the version control system possible on Drupal.org.
- February 2010 - Discussion to select the next version control system was kicked off; at the time, it was a choice between Git, Baazar and Mercucial.
- July 2010 - The Great Git Migration project is created on Drupal.org to manage the related issues and planning.
- February 2011 - First commit to the Git repositories by the migration bot.
- July 2011 - The Great Git Migration project and discussions around version control selection are last updated. This represents the semi-official end of the migration project.
- August 2011 - The “let’s move to Github” wiki/discussion is kicked off.
Our repos are vast
We have over 35,000 projects that total over 50 GB on disk.
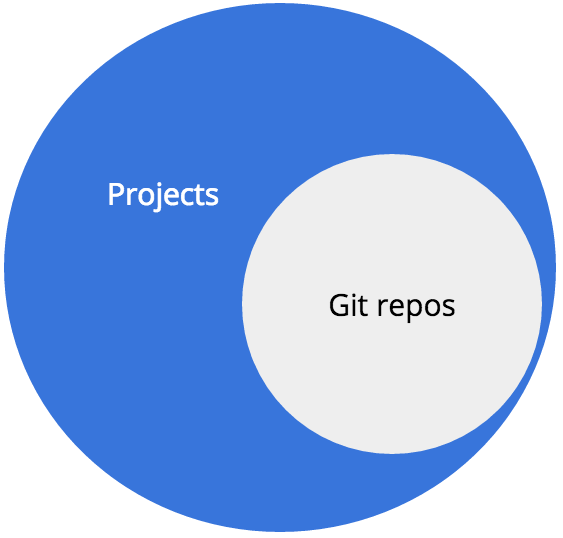
All of the Git repos on Drupal.org are associated with Projects.(e.g. modules, themes, distributions, etc.)
We have issues
At the end of 2015, there were nearly 900,000 issues on Drupal.org. Drupal core alone has over 74,000 issues—over 14,000 of those issues are open. Open issues is not an indicator of code quality, but it is an indicator of how many people have contributed to a project. In general, the more issues a project has, the more challenging it is for maintainers to continuously triage those bug reports, feature requests, plans, tasks and support requests.
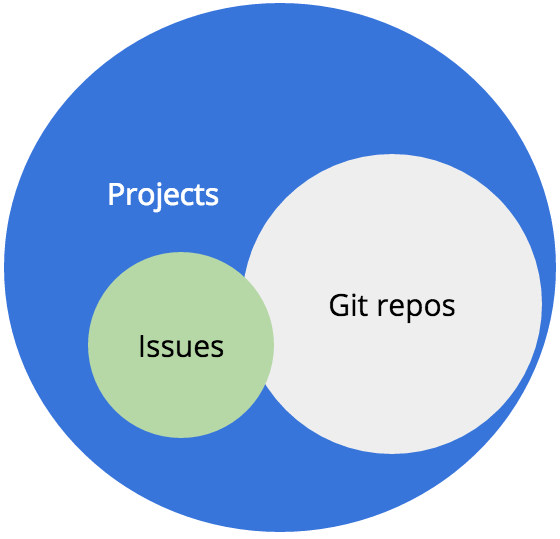
The issue queues are part project management, part bug tracking. As such, they are organic and messy and have lots of rules that have been documented over years of community development. We have 23 pages of documentation dedicated to explaining how to use the issue queues. There is additional documentation dedicated to how to properly fill out an issue for core, for Drupal.org, and for numerous other contributed projects.
Issues are integrated into collaboration on Drupal.org
Those issues belong to projects and are connected to the Git repos through hooks that show a system comment when an issue is related by node ID (issue number) to a commit in Git.
Issues can have patches uploaded to them that are the primary means of suggesting a change to code hosted on Drupal.org. The patch-based workflow has extensive documentation, but it is not a simple task for a novice user to jump in and start contributing.
Most Git hosting solutions (Github, Gitlab, Bitbucket, etc.) either have some version of an issue or at least integrate with an issue tracking system (Jira, Pivotal Tracker, etc.) and provide pull request functionality (a.k.a. merge requests).
Having the same name is where the similarities and consistencies stop. Issues on Drupal.org have status, priority, category, component, tagging and more that are unique to Drupal project workflow. It would be a significant exercise to remap all of those categorizations to a new system.
Packaging
If the projects are what you can browse and find, and the issues are how you collaborate and change the code, the next most important service for Drupal is likely the packaging system.
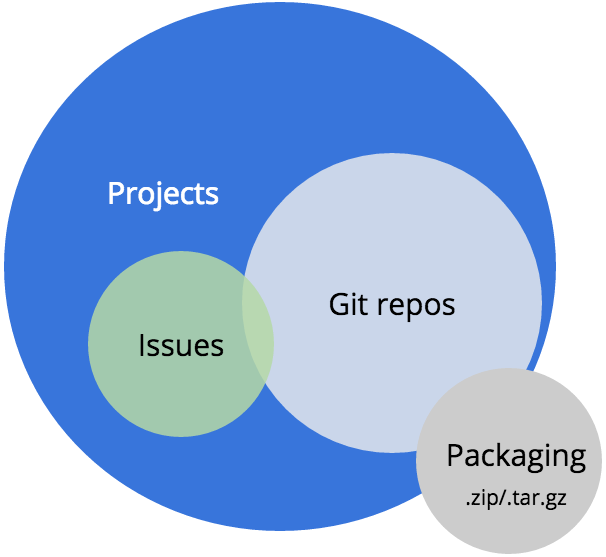
Packaging is based on project maintainers creating a release of the code by associating a branch of the Git repository with the release. Every 5 minutes, our automation infrastructure checks for new releases and will package those releases into a downloadable file to represent the project.
Few developers actually access this directly from the project page anymore. They are much more likely to use Git, Drush, Console or Composer to automate that part of the workflow. Drush, and to some extent Composer, both use the packaged files when a command is issued. Also, the Drupal feature of just putting the code in the correct directory and it will run—with no compiling—is fundamental to the history of Drupal site building.
Updates
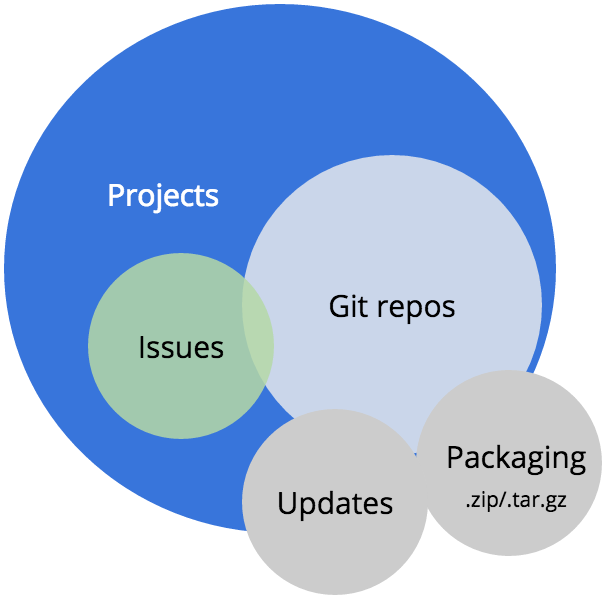
Another crucial Drupal service, updates is built into how Drupal core checks on itself to see if it is up to date.
The 1.3 million plus websites that call home to updates.drupal.org get back XML that is then parsed by that installation’s update status module; that updates module has different names depending on the version of Drupal. Each month, about 12 terabytes of traffic to our CDN is requests for updates XML. Considering this is a bunch of text files, this is an amazing number to consider. Some sites call home once a week, some once a day, and some do it every few minutes. (Really people! Be nice to your free updates service. Telling your server to ask for updates daily is plenty frequent enough.)
Tallying the unique site keys that request this information is how we get our usage statistics. While this is probably not the most precise way to measure our usage, it is directionally accurate. There are plenty of development sites in those stats and plenty of production websites that don’t call home. It should roughly balance out. To be anymore precise, users of Drupal would have to give up some privacy. We’ve balanced accuracy with privacy.
Because of our awesome CDN (thanks, Fastly!), we are able to deliver up to date packages and updates information in milliseconds after we update the underlying data.
Composer
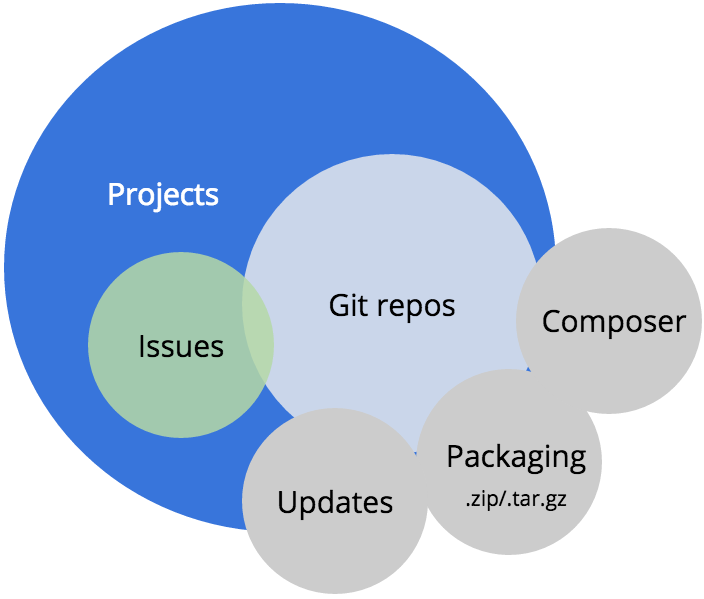
On May 3rd, we launched the alpha version of our Composer endpoints on Drupal.org. If you don’t know about Composer, you should read up on it. Composer is package management for PHP. (It’s similar to what NPM does for Node.js or RubyGems does for Ruby.)
Core developers have been using Composer for some time as a means to manage the dependencies of PHP libraries that are now included in core.
The Composer endpoints allow any Drupal site developer to use composer install to build out their websites.
The new Composer service will also allow contrib project maintainers to using composer.json files to define the requirements for their modules and themes. The service even translates project release versions into semantic versioning. Semantic versioning was the biggest reason we could not “just” use Packagist.org like other projects in the PHP community.
This is all a huge benefit, but more importantly, we now have deep integration between a best practice approach to PHP dependency management and the Drupal.org code repos that can scale to our community needs.
Testing with DrupalCI
Speaking of needs, DrupalCI ran 67,000 test runs in January 2016. Each test run for Drupal core has 18,511 tests per run. That means over 100,000 assertions (steps) in the unit and functional tests that make sure Drupal’s code is stable and that an accepted patch does not create a regression.
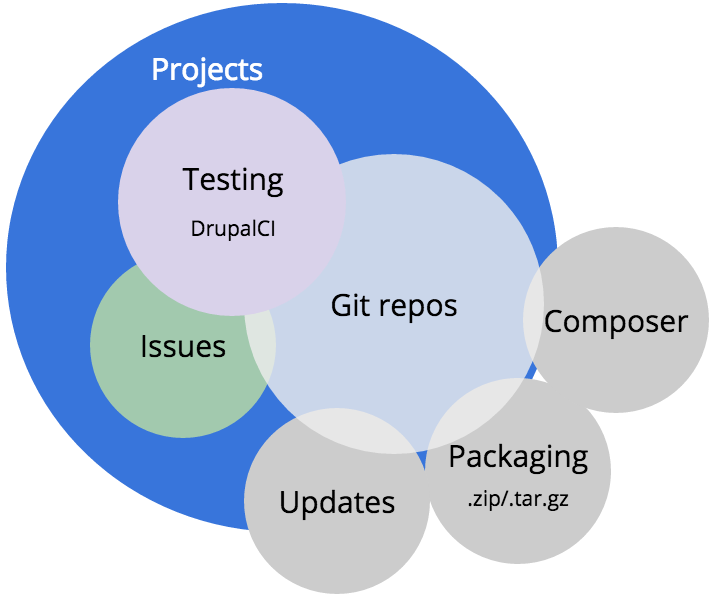
At the time of this post, we are using Amazon Web Services cc2.8xlarge EC2 spot instances for our testbots. These bots are powerful. They have 2 processors with 8 hardware cores. AWS claims they can provide 88 EC2 compute units per instance. They are packed with processing power because we have a lot of tests to run. While there are bigger instances, the combination of price and power allows us to keep Drupal core complete test runs right around 30 minutes. We autoscale up to 20 of these instances depending on demand, which keeps queue times low and allows maintainers to get quick feedback about whether a patch works or not.
I truly believe that getting DrupalCI up and stable is what allowed Drupal 8 to get to a full release last fall. Without it, we would have continued to struggle with test times that were well over an hour and a system that required surplus testbots to be manually spun up when a big sprint was happening. That was costly and a huge time waste.
If anyone asks me “what’s the most important thing your team did in 2015”, I can unequivocally say “unblocking core development to get Drupal 8 released.”
Issue credits
The second most important service we built in 2015—but certainly the more visible—is a system for crediting users and organizations that contribute on Drupal.org.
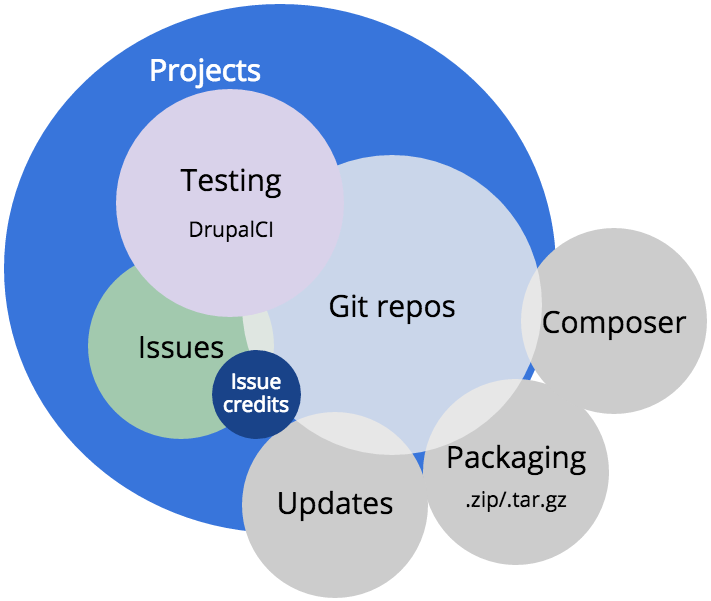
Issue credits sprang forth from an idea that Dries proposed around DrupalCon Austin in June of 2014. At the time, his intent was a means of structuring commit messages or using commit notes to provide the credit. Eventually, we shifted the implementation to focus on participation in issues rather than code commits. This made it possible to credit collaboration that did not result in a code change.
I won’t get into the specifics; I wrote a A guide to issue credits and the Drupal.org marketplace earlier this year. Issue credits have been extremely successful.
As there name implies, we store the data about credits as a relationship to closed issues. Issue credits touch issues, projects, users, organizations and the marketplace on Drupal.org.
Why not just migrate all of this complexity to Github?
Why can’t we just move all this to Github?
— said lots of people, often
To be fair, this is a challenging discussion. Angie Byron (webchick) wrote an amazingly concise summary of the Github issue on Groups.drupal.org.
That wiki/discussion/bikeshed was heated. The conversation lasted over two years. I started as CTO about 6 months into the conversation. Along with a couple of other themes, the Github move has been a constant background conversation that has defined much of my time leading the Drupal.org team.
How are these services connected?
To truly understand the problem of a migration of this scale, we have to look at how all of the major Drupal.org services are connected.
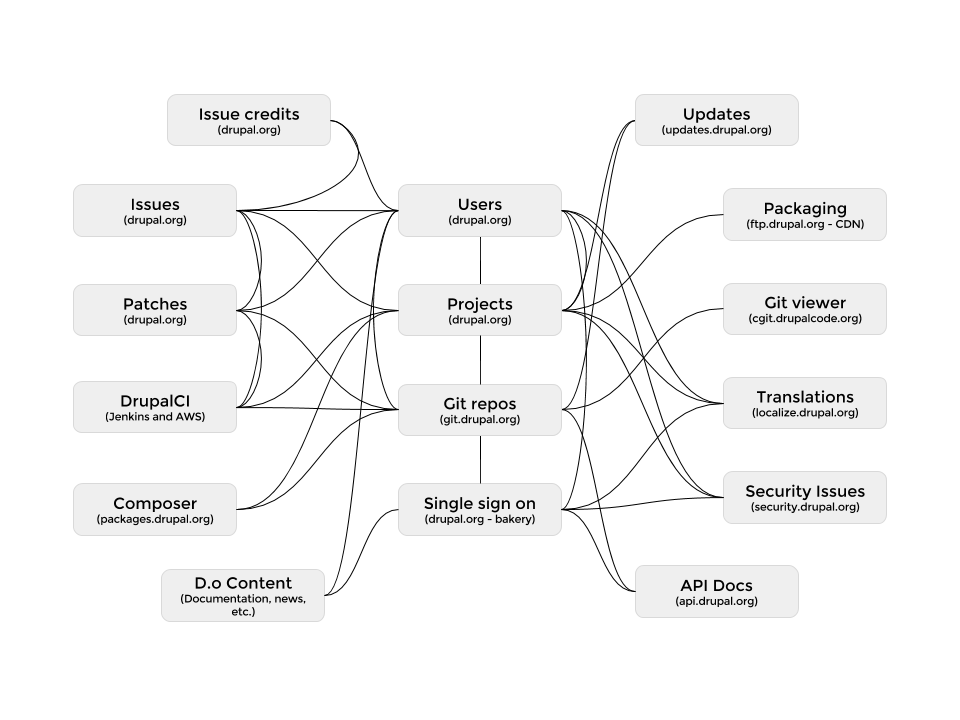
Each block in this diagram is a service. Each line is a point of integration between the services. Some of these services are on Drupal.org or subsites with thousands of lines of custom code defining the interactions. Other services are not built in Drupal and represent projects in Java (Jenkins) or Python (our Git daemon) with varying degrees of customization and configuration.
As the diagram suggests, it is truly a web of integrations. Pull one or more services out of this ecosystem and you have to either refactor a ton of code or remove a critical component of how the community collaborates and how our users build sites with Drupal.
It’s kinda like a great big game of Jenga.
What would a migration to Github require?
Please believe me when I say that if it were “easy” or “simple”, we would have made either moved to Github or at least upgraded our Git collaboration with nifty new tools on our own infrastructure.
However, disrupting the development of Drupal 8 would have been devastating to the project. We were correct to collectively backlog this project.
So if we were to try this migration now, what would it take? First, you have to consider the services that Github would effectively replace.
Github replaces:
- Git repositories
- Issues
- Patches (they would become pull requests)
- Git viewing (and we’d get inline editing for quick fix and onboarding)
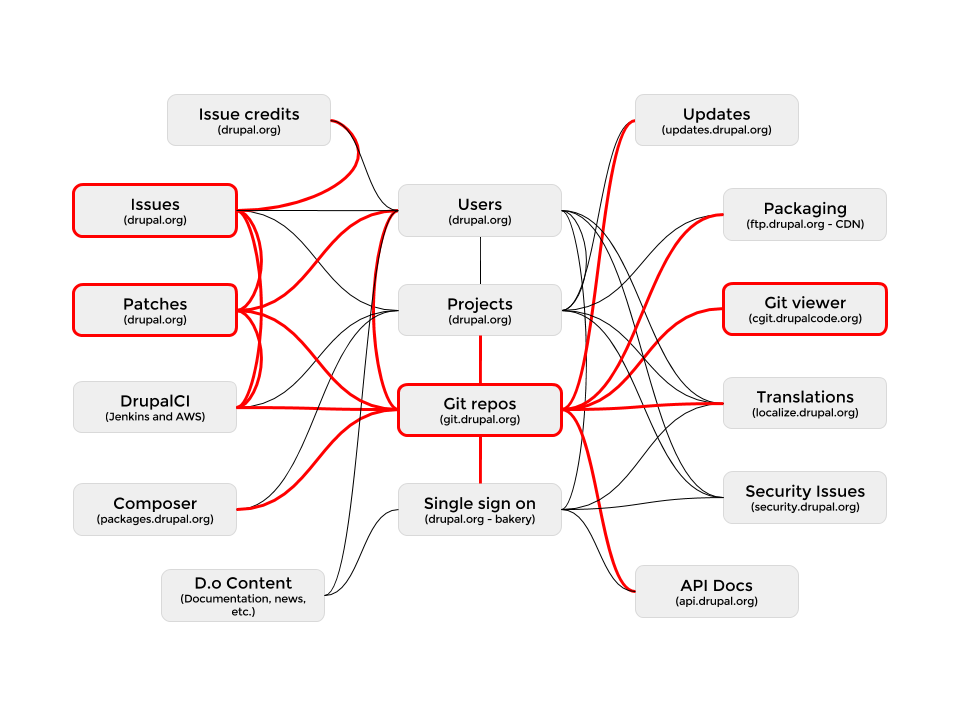
That’s four (4!) services that we would not have to maintain anymore. Awesome! Cost savings everywhere! Buy a boat!
Wait a second. You have 16 integration points that you need to refactor. Some of them would come with the new system. Issues, pull requests, repos and the viewer would all just work with huge improvements. That leaves us with 12 integration points that would require a ton of discovery and refactoring.
- Users - we have 100,000 Drupal.org users that are pretty engaged. (We have over 1 million user accounts—but that number is likely a little inflated by spam accounts.) Do we make them all get Github accounts? Do we integrate Github login to Drupal.org? Do we just link the accounts like Symfony does?
- Projects - Github is not a project browsing experience. Drupal.org is a canonical repository where the “one true project” lives for packaging and updates. At the very least, we have to integrate our projects with Github. Does that mean we have to keep a Git repo associated to the project that has hooks to pull in changes from Github?
- Testing - One of the less complex integration refactors would be getting DrupalCI integrated with pull requests. That effort would still be a months long project.
And DrupalCI would be its own effort to migrate to another testing service because it is tailored to the issue queue workflow and tightly integrated with projects.
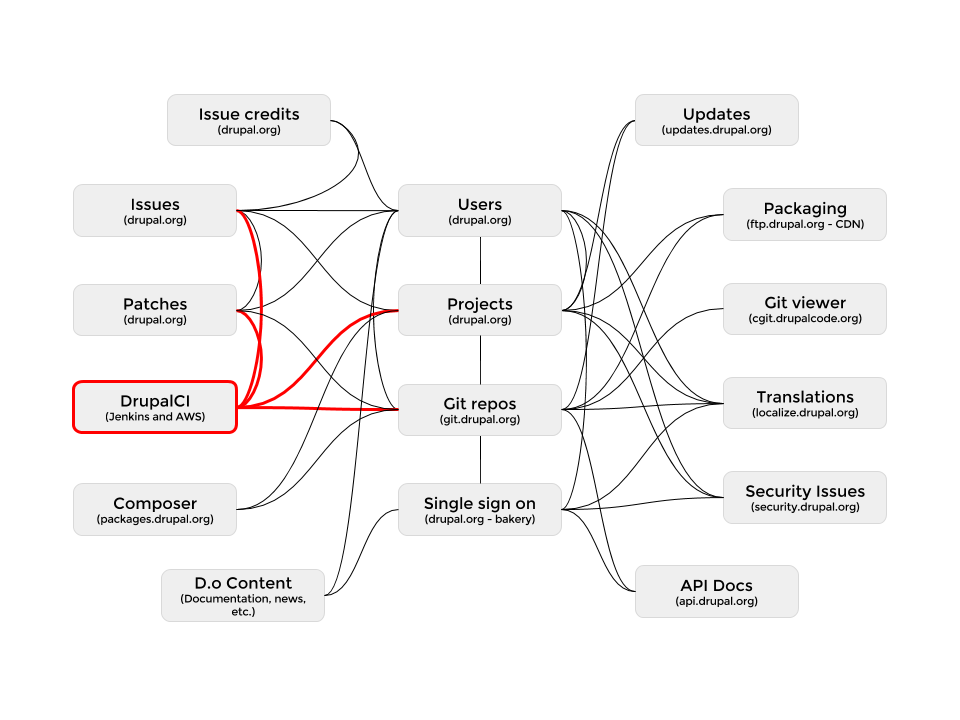
Those are just a few of the major integration points.
I have a personal goal to detail every single integration and get that documented somewhere on Drupal.org. I don’t think that level of documentation will increase the ability for others to contribute to the Drupal.org infrastructure—though that would be a pleasant side effect. I do think it is necessary for us to continue to support and maintain our systems and ensure that all of the tribal knowledge from the Drupal.org team can be passed on.
What would it cost?
I have joked that it would take roughly 1 million dollars (USD) to complete a Github migration. (Cue Dr. Evil.) That is only partially meant in jest.
As anyone who has estimated a large project knows, there is a point of uncertainty that leads project owners to guess at what they are willing to pay for the project.
If we take the four biggest lifts in the Drupal project’s history, what do we get?
- Drupal.org redesign - There were tens of people involved in the project, hundreds giving feedback. The timeline was about a year from start to implementation.
- The Great Git Migration - There were tens of people involved in the project. Far fewer users gave feedback, but the project took about two years from brainstorming to initial commit to the Git repos—with a few months of clean up after.
- Drupal.org upgrades to Drupal 7 - The project took about two years with tens of people involved in about 8 months of clean up issues.
- Drupal 8 - 5 years of development by over 3,000 contributors.
I don’t think than anyone would argue that each of these projects would have been bid at well over $1 million. I would put a migration to Github at somewhere between the complexity of The Great Git Migration and Drupal 8.
In none of these cases did the Drupal Association actually spend $1 million USD in project dollars. However, in all of the projects, there was lengthy discussion followed by substantial volunteer contribution, and then a significant bit of paid work to finish the job. It’s a pattern that makes sense and will likely repeat itself over and over.
Would it be worth it?
I’m going to go back to the summary on the Github discussion. There are reasons why both options seem to be the best possible option or the worst possible option.
Would a best practice workflow and toolset be worth the change? Absolutely. Github (or Gitlab) tools are easier for newcomers to learn. Further, because we are using PHP and Javascript libraries that are hosted on Github, we could get contributions from developers and designers that are involved in those projects and do not wish to have account on Drupal.org.
The drawbacks are considerable. We cannot afford a full migration right now. Dries put it well at DrupalCon Los Angeles during core conversations. The Drupal Association is not a bag of money. With significant growth of revenue, there is a long term possibility of more paid developer resources, but not in the short term. It is too much to ask volunteers to give up a year of their life to run the project as a community initiative. That leads to burn out and frustration.
We should also consider whether the disruption to the current collaboration workflow will be worth it. I don’t think so. Not if that disruption meant stalling the update of contrib projects that are critical to solidifying Drupal 8 adoption. (Though I could argue that much of this upgrade to Drupal 8 work is being performed on Github as some—perhaps many—developers prefer those tools.)
Is there a middle ground?
Drupal spends a lot of time getting to the middle ground. Many of the best innovations in Drupal come from getting to the middle ground—from reaching a general consensus and then allowing someone who has support and time iron out the details.
So for the first step, we should add functionality to projects on Drupal.org that allow maintainers to shift their workflow to Github while still publishing their project on Drupal.org. This allows the canonical browsing of projects, the continued support of the security team, and most importantly the continued distribution of Drupal through Composer, release packaging and the updates system.
We have a solid way forward for these integrations as the requirements are narrow enough in scope to accomplish in a 4-6 month timeframe using dedicated resources. We would still need to figure out how to award an issue credit to someone that participated in an issue on Github. We might be able to institute commit credits that could be parsed into issue credits from the participation on Github, but it would not be as inclusive as the current model.
It would be important to phase in this new feature rather than make a wholesale change. Once that integration is in place, we could extend DrupalCI to test pull requests similar to how we currently test patches submitted to an issue.
Stay flexible
We need to be flexible. GitHub has a lot of potential as tool for open source distribution and collaboration—likely for the foreseeable future. However, not every major project is on GitHub. The Linux Kernel uses Git repositories with cli tools and a patch-based workflow that relies heavily on email. It works for them. Wordpress is still on Subversion—even though they’ve started to accept some pull requests on GitHub. These projects are poised to make the right decision rather than a rash decision.
The sky will not fall if we keep our current model, but we are losing opportunities to grow as a community of contributors. Rather than a wholesale migration, we must understand the value and history of this web of integration points. Targeting our efforts on specific integrations points can achieve our goal of opening our doors to the developers who live and breathe GitHub, without losing the character of our collaboration. And in the long run, this focus on services and integrations can make us more adaptable to the next change in the broader development landscape.
Special thanks to Tim Lehnen, Ryan Aslett, Rudy Grigar and Neil Drumm for helping me pull this data together and to the rest of the Drupal.org team for reviewing the post for typos.