
Posted on
You may be familiar with the Entity Usage module. It's been around since early 2018 for modern Drupal sites to track content, media, taxonomy terms, blocks... really any entity type.
Once enabled, you can configure these entity types to be a source or a target and define whether it has a "Usage" local task.
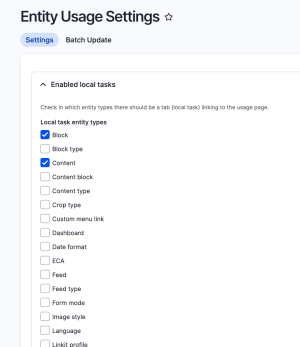
Several types of tracking plugins allow you to check and see if an entity is in use as an embed in CKEditor, referenced by field, or within a layout builder relationship.
The usage tab will show you these references even letting the editor know if the usage is in a previous revision or translation of the source entity.
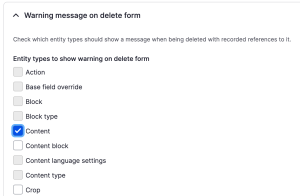
For many clients, I've configured entity delete forms to warn an editor if the entity they are deleting is used by another source entity. This is great for ensuring unexpected broken links.
A recent project needed to audit a number of documents (mostly PDFs) that were unexpectedly appearing in Google search results. The easiest way to identify documents that needed to be archived was to review unused media.
I took a two-prong approach to showing usage and attempting to show unused media on the site.
First, I added Entity Usage Views Field so that I could add a simple count to views like the administrative media view. This does not require any relationships to be added to the view.
A limitation of this field is that it does not allow you to filter by the usage count.
To get around this for a special "Unused media" view, I added the media usage relationship and then used aggregation to sum the usage count and group media titles. This aggregated value could also be used as a filter by looking to see if the usage count was null.



For media that was appropriately embedded within the site, this worked great. However, I have a saying, "editors gonna edit." It turns out that our editors had done thinks like copying the media download link and pasting an absolute URL into a link with CKEditor instead of embedding documents. Further, we discovered that some editors had access to upload files directly to Amazon's S3 file service and were linking to these PDFs directly.
To solve for these edge cases—which were relatively rare—we created an administrative view to audit our content and look in the body field using group of filters matching the various patterns we knew would need auditing.
The end result was shocking. For a site that only launched three years ago, there were over 14,000 PDF documents that had been created and just over 7,000 of those PDFs were not embedded anywhere on the site. Archiving these documents no only will free up a considerable amount of disk storage, it also helps reduce the burden of auditing those documents for accessibility as a part of the site's 2026 deadline for meeting WCAG AA compliance.
Does media tracking sound like a problem you need help solving? Connect with me on LinkedIn and let's talk.